iOS 方案之本(Essence of Workaround in iOS)是我新写的一个专题。在很多大厂的各路优化方案中,只是告诉了我们为了达到目的怎么去做,但是并没有说这个方案的本质原因是什么。这个专栏就是为了格物致知,从原理层面来讲述方案背后的原理。
背景
在很多大厂对外公布的 iOS 提高编译速度的方案中都会有这一种优化方案:
将 Build Setting 的 Debug Information Format 中的 Debug 改成 DWARF。
方案出处:
- iOS 微信编译速度优化分享
- HACKERNOON - Speed up Swift compile time
-
AREK HOLKO - Speeding up Development Build Times With Conditional dSYM Generation
等等。
溯源 DWARF
DWARF 全名是 Debugging with Attribute Record Formats,是一种调试信息的存放格式。
DWARF 第一版发布于 1992 年,主要是为 UNIX 下的调试器提供必要的调试信息,例如内存地址对应的文件名以及代码行号等信息,通常用于源码级别调试使用。另外通过 DWARF,还能还原运行时的地址成为可读的源码符号(及行号)。
DWARF 调试信息简单的来说就是在机器码和对应的源代码之间建立一座桥梁,大大提高了调试程序的能力。
iOS 中引入 DWARF 这种调试信息格式,其实也是顺应历史的潮流,因为 DWARF 已经在类 UNIX 系统中逐步替换 stabs(symbol table strings),成为一种主流的调试信息格式。使用 GCC 或者 LLVM 系列编译器都可以很方便的生成 DWARF 调试信息。
在 《DWARF详解》这篇博客中,作者给出了一个 DWARF 的发展历史以及它的一些竞品,这里我引用一下:
DWARF 发展历史
| DWARF 版本 | 发布时间 | 社区 |
|---|---|---|
| DWARF1 | 1992 | Unix SVR4, PLSIG, UnixInternational |
| DWARF2 | 1993 | PLSIG |
| DWARF3 | 2005 | Free Standards Group |
| DWARF4 | 2010 | DWARF Debugging Format Committee |
| DWARF5 | 2017 | DWARF Debugging Format Committee |
DWARF 的竞品
| 调试信息格式 | 发布时间 | 使用平台 |
|---|---|---|
| stabs (symbol table strings) | 1981 | 曾广泛使用于 UNIX 环境,逐步被 DWARF 替代 |
| COFF (Common Object File Format) | 1983 | UNIX System V(AT&T), AIX(IBM, XCOFF), DEC、SGI(ECOFF) |
| IEEE695 | 1990 | 虽然是 IEEE 标准,但是支持少数几种处理器架构,当前几乎没有任何主流平台使用 |
| PECOFF (PE/COFF) | 1995 | Windows PE,Windows NT,COFF 最流行的变种 |
| OMF (Object Module Format) | 1995 | CP/M, DOS, OS/2, embedded systems |
| PDB (Program database) | Windows, Microsoft Visual Studio 的默认调试格式 |
DWARF 的使用探索
DWARF 和 dSYM 编译时生成
上文中我们提及到了,DWARF 主要为调试器服务。以下文章我们来探索一下 DWARF 和 dSYM 是在编译流程什么阶段生成的。首先我们知道我们的源码文件的编译流程是这样的:
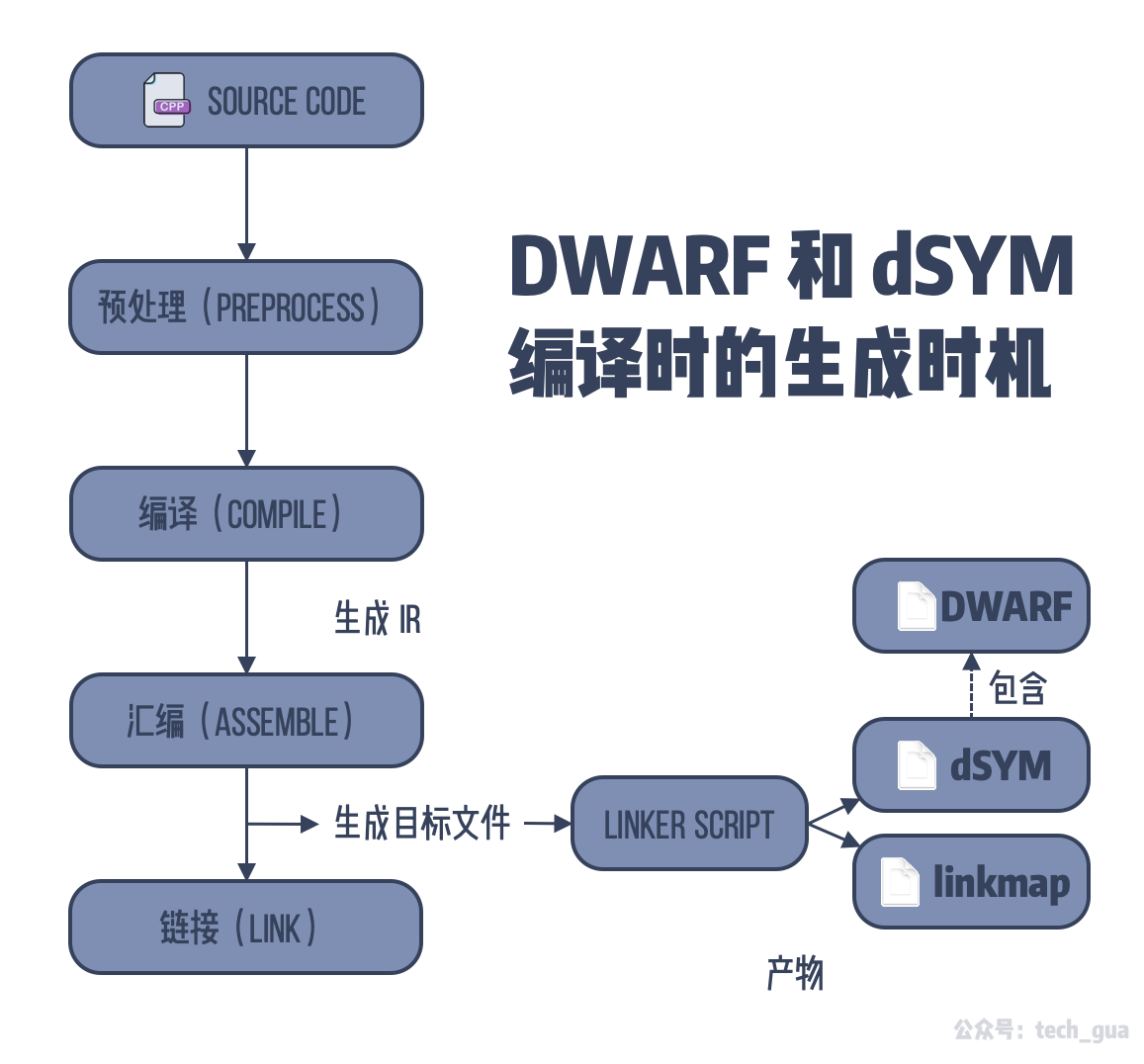
从这里我们可以看到 dSYM 文件和 DWARF 文件在编译时的生成时机,其实是根据目标文件进而通过链接脚本来生成这些我们需要的产物。其实我们学过编译原理都知道这是一个两步链接(Two-pass Linking)方法中的第二步 —— 符号解析与重定位。你可以通过对 .o 目标文件的进行 objdump 来查看地址的分配情况。
使用 Clang 生成 DWARF 调试信息
为了进一步认识 DWARF 是如何生成的,单看上面图你可能还是觉得抽象,我们来做一个实验。其实这个过程十分简单,因为 Clang 编译器已经将生成调试信息 DWARF 的过程封装在一个参数 -gdwarf-4 内。
生成 DWARF 文件
创建一个 cpp 源码文件:
$ touch test.cpp写 Demo 的源代码:
int foo(int x, int y) {
return x + y;
}
int main() {
int ans = foo(1, 2);
return 0;
}使用 Clang 编译并生成 DWARF4 编译信息:
$ clang -O0 -gdwarf-4 test.cpp -o test编译完成后,发现当前目录下已经多了一个 test.dSYM 目录:
$ tree
.
├── test
├── test.cpp
└── test.dSYM
└── Contents
├── Info.plist
└── Resources
└── DWARF
└── test使用 lldb 进行调试
使用 lldb 调试 test,并观察 test.dSYM 是否有作用。使用以下命令来启动 lldb 并设置调试程序为 test,交互命令中使用 b foo 增加 foo 方法断点 ,并输入 run 运行程序:
$ lldb test
(lldb) target create "test"
Current executable set to 'test' (x86_64).
(lldb) b foo
Breakpoint 1: where = test`foo(int, int) + 10 at test.cpp:3:10, address = 0x0000000100000f6a
(lldb) run
Process 39727 launched: '/Users/bytedance/Desktop/cool/lab/test' (x86_64)
Process 39727 stopped
* thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
frame #0: 0x0000000100000f6a test`foo(x=1, y=2) at test.cpp:3:10
1
2 int foo(int x, int y) {
-> 3 return x + y;
4 }
5
6 int main() {
7 int ans = foo(1, 2);
Target 1: (test) stopped.
(lldb)此时我们发现,lldb 中的方法、行号以及断点位置已经全部显示出来了。
对比无 DWARF 情况
也许你可能有疑问,如果不生成 DWARF 会是什么样的。我将 test.cpp 复制一份到 test2.cpp 并使用 Clang 不加 -gdwarf-4 参数生成目标文件:
$ cp test.cpp test2.cpp # 复制源码文件
$ clang test2.cpp -o test2 # 编译并生成目标产物
$ lldb test2 # lldb 调试
(lldb) target create "test2"
Current executable set to 'test2' (x86_64).
(lldb) b foo
Breakpoint 1: where = test2`foo(int, int), address = 0x0000000100000f60
(lldb) run
Process 45672 launched: '/Users/bytedance/Desktop/cool/lab/test2' (x86_64)
Process 45672 stopped
* thread #1, queue = 'com.apple.main-thread', stop reason = breakpoint 1.1
frame #0: 0x0000000100000f60 test2`foo(int, int)
test2`foo:
-> 0x100000f60 <+0>: pushq %rbp
0x100000f61 <+1>: movq %rsp, %rbp
0x100000f64 <+4>: movl %edi, -0x4(%rbp)
0x100000f67 <+7>: movl %esi, -0x8(%rbp)
Target 0: (test2) stopped.发现断点是停留在汇编层面的,这就说明不生成 DWARF 调试信息格式文件的时候,在调试阶段是无法对方法地址进行符号化的。另外用户层面来说,这种断点的可读性是非常差的!当然如果你对汇编很有造诣的话,也是可以查出问题的!😀
产物区别实验
通过这个实验,我们发现其实 DWARF 文件是对我们调试有利的东西。我们来看一下它与DWARF with dSYM 的区别是什么?
由于我的 Demo App 是使用 CocoaPods 进行集成的,而 dSYM 是根据 Target 来做区分的。所以我们在 CocoaPods 中,增加 post_install 脚本,将所有的 Pod Target 的 Build Setting 全部修改一下:
post_install do |installer|
# 由于我开启了 muti project 模式,所以在 installer 中不能直接访问 pods_targets 成员
installer.generated_projects.each do |project|
project.targets.each do |target|
target.build_configurations.each do |config|
config.build_settings['DEBUG_INFORMATION_FORMAT'] = 'dwarf'
# config.build_settings['DEBUG_INFORMATION_FORMAT'] = 'dwarf-with-dsym'
end
end
end
end重新 pod install ,为了避免增量不生效的问题,我们在 pod install 时最好增加 --clean-install 参数保证重新生成 Pod Target,并且生成之后,使用 Build Setting 的 Level 功能来验证一下 xcconfig 是否已经发生变化。
之后,对 App 进行两次 Archive 观察现象,结果如下:
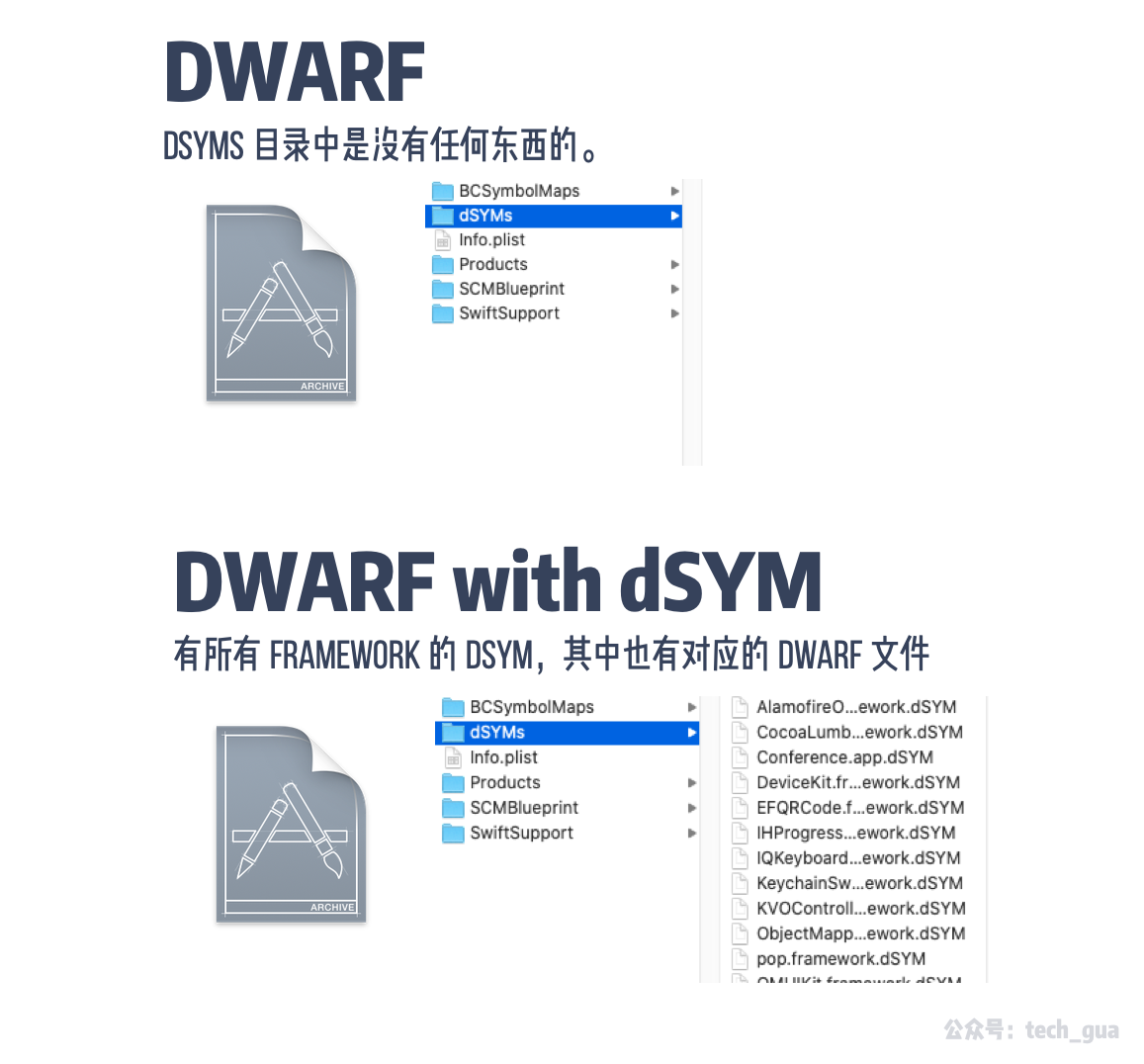
发现,在 DWARF 时,dSYMs 是不包含任何东西的,但是它没有生成 DWARF 文件吗?其实我们在 Xcode 中的 Quick Helper 能找到答案:
Summary The type of debug information to produce. * DWARF: Object files and linked products will use DWARF as the debug information format. [dwarf] * DWARF with dSYM File: Object files and linked products will use DWARF as the debug information format, and Xcode will also produce a dSYM file containing the debug information from the individual object files (except that a dSYM file is not needed and will not be created for static library or object file products). [dwarf-with-dsym]
当我们选择 DWARF 时,其实就已经使用 DWARF 调试描述文件了,所以这个 DWARF 文件依旧会生成;不同的是当选择 DWARF with dSYM 时,Xcode 还会生成一个 dSYM 文件,其中显式包含 DWARF 从而帮助我们根据地址,找到方法符号及信息。
这也就是为什么要在 release 下要开启 DWARF with dSYM ,因为我们要去映射地址所对应的方法符号,方便我们排查问题。
性能耗时实验
到底减少生成 dSYM 文件能带来多少的受益呢?我们简单实验一下。
继续使用这个 Demo APP 来进行实验(控制 Build 初期 CPU 负载 2% 左右,温度在 55 度,内存负载 30%),当 Debug Information Format 使用 DWARF 时,全量无缓存 Archive 10 次平均耗时 79.4 秒;使用 DWARF with dSYM 时,平均耗时 90.1 秒。可能项目比较小,所使用的 Pod 仓库较少,编译源码文件也较少,所以并不是很明显。但是还是有一些微小的提升。
总结
通过这个优化方案,延伸到 DWARF 调试格式文件的探索,让我们对编译器的编译过程、调试器的调试符号查找过程有了较为深入的认识,也明白了为什么这种优化可以带来编译性能的提升。优化方案并不仅仅是一个方案,它可以成为我们研究某一个知识的入口,从而带来新的收获。
特别感谢
感谢群友 @xi_lin 和 @sjl1358979501 对于结果的二次验证。
引用
