摘要:这个 Session 涉及了 Swift 的新语法特性和 Swift Macro 的话题,这些功能对于编写更加灵活和健壮的 API 以及高质量代码起到了很大的帮助。此外,也深入探讨了在受限环境下使用 Swift 的优势,并讨论了 Swift 在适配多种平台设备和语言方面的灵活性。
本文基于 Session 10164 梳理。
审核:
stevapple:学生,Swift/Vapor 社区贡献者
kemchenj:老司机技术核心成员 / 开源爱好者 / 最近在做 3D 重建相关的开发工作
今年是 Swift 的一次重大更新,这个 Session 将和大家一起聊聊 Swift 语言今年的一些改进、简洁的语法糖以及一些强大的新 API 的使用。一年前,Swift 项目的核心团队宣布了成立 Language Steering Group ,主要负责监督 Swift 语言和标准库的修改。从这之后,Language Steering Group 已经审核了 40 多个新的提案,这些会覆盖到我们今天所要讨论的几个。
有很多社区提案都有相同的思路和看法,所以我们会将这些类似的提案进行合并。而在这之中,Swift Macro(在 C 的中文教材中,一般称作宏,下文继续使用 Macro 进行代替)是提及最多的一个提案,所以我们后文也会具体讨论 Swift 5.9 中关于 Swift Macro 的新特性。
当然,语言的演进只是 Swift 社区工作的一部分,一门成功的语言需要的远不止这些,它还需要配合优秀的工具链、多平台的强大支持以及丰富的文档。为了全方位的监控进展,核心团队也正在组建一个 Ecosystem Steering Group ,这个新的团队也在 swift.org 的博客中有所提及,我们可以一起期待一下这个团队的进一步公告。
现在我们进入正题,来讨论一下今年 Swift 语言的更新。
if/else 和 switch 语句表达式
Swift 5.9 中允许 if/else 和 switch 作为表达式,从而输出返回值。这个特性将会为你的代码提供一种优雅的写法。例如,你如果有一个 let 变量,其赋值语句是一个非常复杂的三元表达式:
let bullet =
isRoot && (count == 0 || !willExpand) ? ""
: count == 0 ? "- "
: maxDepth <= 0 ? "▹ " : "▿ "
对于 bullet 变量的赋值条件,你可能会觉得可读性十分差。而现在,我们可以直接使用 if/else 表达式来改善可读性:
let bullet =
if isRoot && (count == 0 || !willExpand) { "" }
else if count == 0 { "- " }
else if maxDepth <= 0 { "▹ " }
else { "▿ " }
如此修改后,我们的代码会让大家一目了然。
另外,在声明一个全局变量的时候,这种特性会十分友好。之前,你需要将它放在一个 closure 中,写起来是十分繁琐。例如以下代码:
let attributedName = {
if let displayName, !displayName.isEmpty {
AttributedString(markdown: displayName)
} else {
"Untitled"
}
}()
但是当我们使用这个新特性,我们可以直接去掉累赘的 closure 写法,将其简化成以下代码:
let attributedName =
if let displayName, !displayName.isEmpty {
AttributedString(markdown: displayName)
} else {
"Untitled"
}
因为 if/else是一个带有返回值的表达式,所以这个特性可以避免之前啰嗦的写法,让代码更简洁。
Result Builder 相关工具链优化
Result Builder (结果生成器)是驱动 SwiftUI 声明式语法的 Swift 特性之一。在前几个版本中,Swift 编译器需要花费很长的时间来确定错误,因为类型检查器搜索了大量无效路径。
从 Swift 5.8 开始,错误代码的类型检查速度将大幅度提升,对错误代码的错误信息现在也更加准确。
例如,我们来看下以下代码:
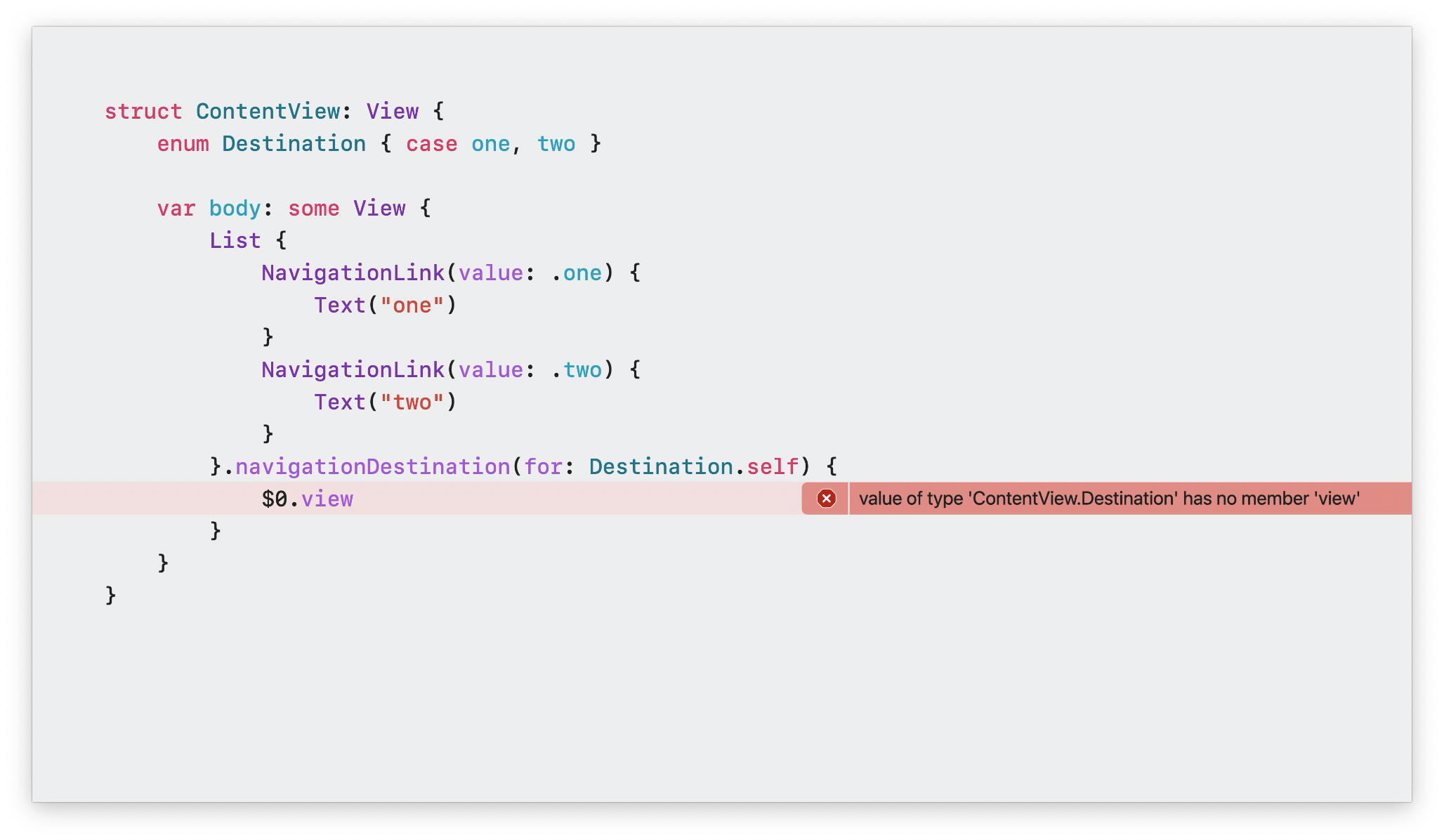
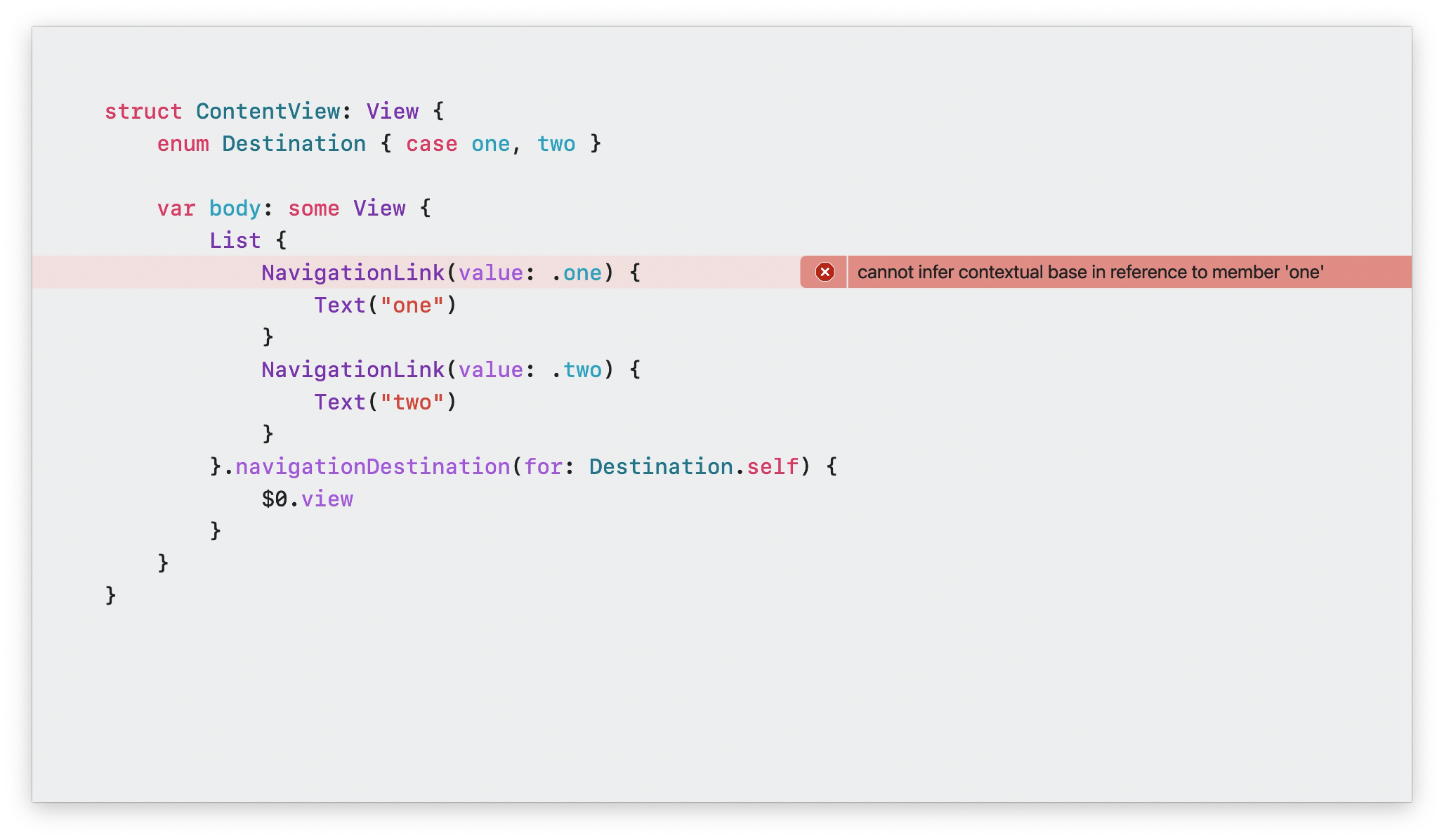
在这个代码中,核心的问题就是 NavigationLink(value: .one) 中,.one 是一个类型错误的参数。但是在 Swift 5.7 旧版本中,会报出如图中展示的错误。Swift 5.8 对 Result Builder 诊断做了优化,不仅提高了诊断的准确性,而且也大幅度优化了时间开销。在 Swift 5.8 及之后的版本中,你将会立即查看到正确的语义诊断错误提示,例如下图:
repeat 关键字和 Type Parameter Pack
在日常使用 Swift 语言中,我们会经常使用 Array ,并结合泛型特性来提供一个存储任何类型的数组。由于 Swift 具有强大的类型推断能力,使用时只需要提供其中的元素,Swift 编译器将会自动推断出来这个数组的类型。
但是在实际使用中,这个场景其实具有局限性。例如我们有一组数据需要处理,且它们不仅仅是单一类型的 Result,而是多个类型的 Result 入参。
struct Request<Result> { ... }
struct RequestEvaluator {
func evaluate<Result>(_ request: Request<Result>) -> Result
}
func evaluate(_ request: Request<Bool>) -> Bool {
return RequestEvaluator().evaluate(request)
}
这里的 evaluate 方法只是一个实例,因为在实际使用过程中,我们会接收多个参数,就像下面这样:
let value = RequestEvaluator().evaluate(request)
let (x, y) = RequestEvaluator().evaluate(r1, r2)
let (x, y, z) = RequestEvaluator().evaluate(r1, r2, r3)
所以在实现的时候,我们还需要实现下面的这些多入参泛型方法:
func evaluate<Result>(_:) -> (Result)
func evaluate<R1, R2>(_:_:) -> (R1, R2)
func evaluate<R1, R2, R3>(_:_:_:) -> (R1, R2, R3)
func evaluate<R1, R2, R3, R4>(_:_:_:_:)-> (R1, R2, R3, R4)
func evaluate<R1, R2, R3, R4, R5>(_:_:_:_:_:) -> (R1, R2, R3, R4, R5)
func evaluate<R1, R2, R3, R4, R5, R6>(_:_:_:_:_:_:) -> (R1, R2, R3, R4, R5, R6)
如此实现之后,我们就可以接收 1 - 6 个参数。但是好巧不巧,如果需要传入 7 个参数:
let results = evaluator.evaluate(r1, r2, r3, r4, r5, r6, r7)
对于这种尴尬的场景,在旧版本的 Swift 中就需要继续增加参数定义,从而兼容 7 个入参的场景。但是 Swift 5.9 将会简化这个流程,我们引入 Type Parameter Pack 这个概念。
func evaluate<each Result>(_: repeat Request<each Result>) -> (repeat each Result)
我们来看引入 Type Parameter Pack 概念之后我们将如何修改这个场景。
<each Result>- 这里代表我将创建一个名字叫Result的 Type Parameter Pack;repeat each Result- 这是一个 Pack Expansion,它将 Type Parameter Pack 作为实际上表示的类型。其实这里你可以理解成(each Result)...,即 Type Parameter Pack 类型的不定参数。所以repeat关键字更像是一个运算符(Operator);
通过这样定义,我们就可以传入不受限制个数的参数,并且可以保证每一个入参都是独立泛型类型。
当然这个特性,最大的受益场景就是 SwiftUI ,因为当一个 View 内嵌多个 View 的时候,SwiftUI 官方的方法就是通过泛型以及 Result Builder 进行设计的,并且最大的子 View有 10 个为上限的数量限制。当引入了 Type Parameter Pack 这个特性之后,限制将被突破,API 设计也更加简洁和易读。
Stevapple: type parameter pack 是 variadic generics(可变泛型)系列 feature 的一部分,更大的范畴上是增强 Swift 泛型系统的一部分。Variadic generics 的概念其实可以这么理解:generics 是对类型进行抽象,而 variadic generics 希望在此基础上增加对参数数量的抽象。具体的提案可以查看这里。
Macro
在 Swift 5.9 中,对于 Macro 的支持是重大的更新。通过 Macro ,你可以扩展语言本身的能力,消除繁琐的样板代码,并解锁 Swift 更多的表达能力。
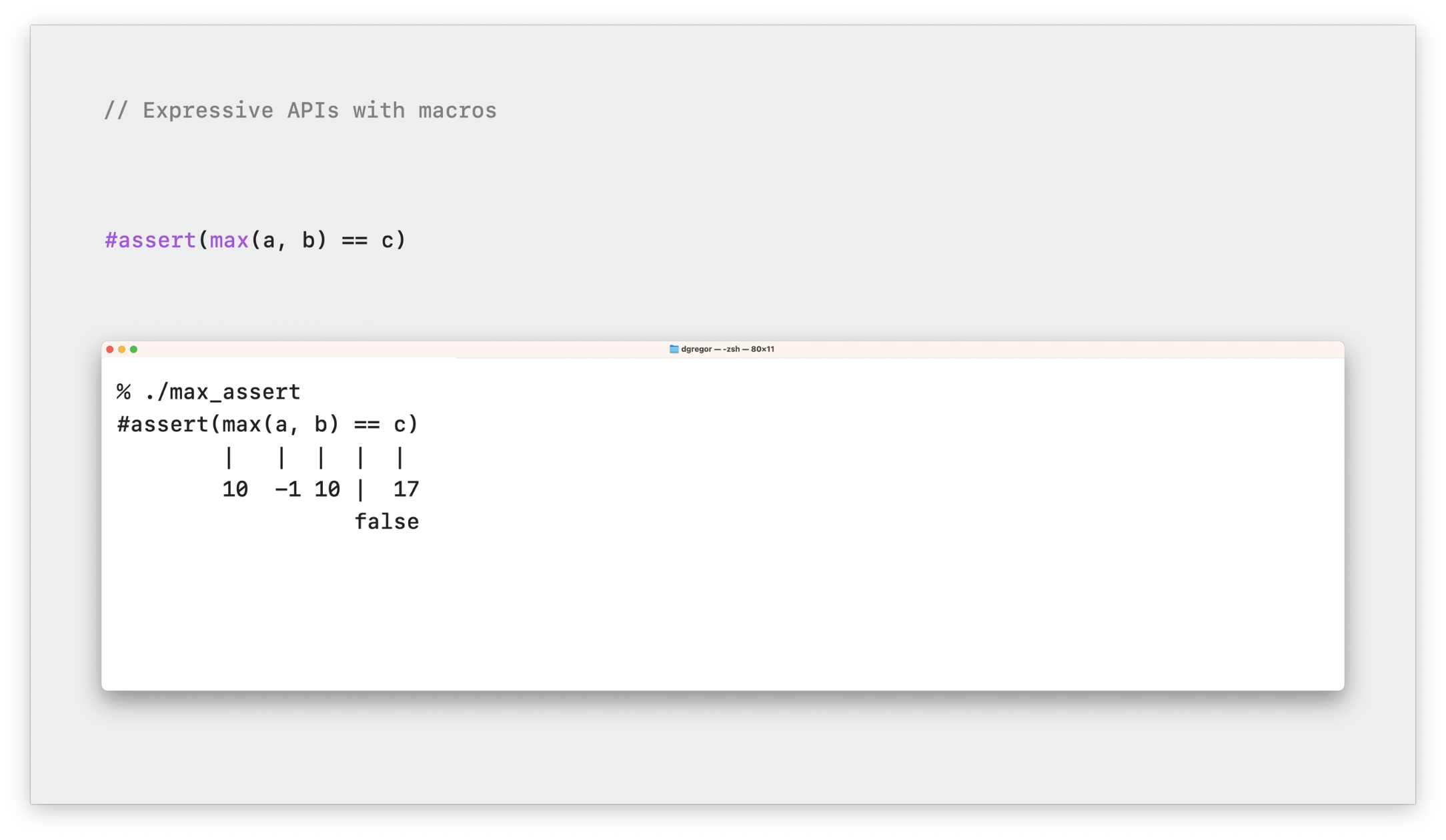
我们先来看断言(assert)方法,它是用于检查一个条件是否为 true。
assert(max(a, b) == c)
如果是 false ,断言将停止程序运行。在通常情况下,你获得到错误信息很少,因为你需要修改每一处断言调用,增加 message 信息,这样才能有效定位很多边界情况问题。
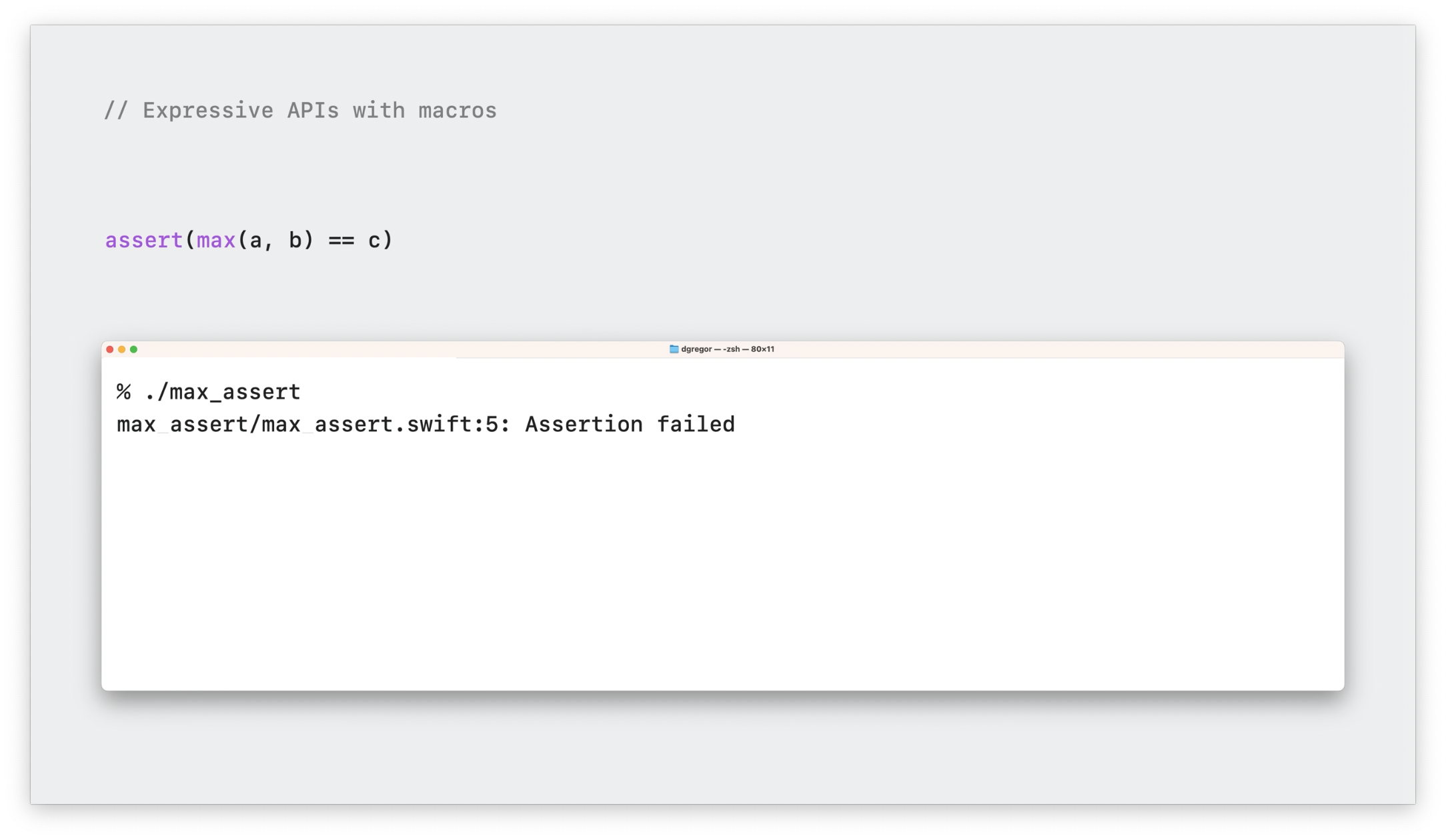
其实 XCTest 也提供了一个 XCAssertEqual 方法,可以展示更多的错误信息。但我们实际操作后发现,即使我们知道了两边的值,也无法定位到到底是 max 方法的错误,还是右边 c 变量的问题。
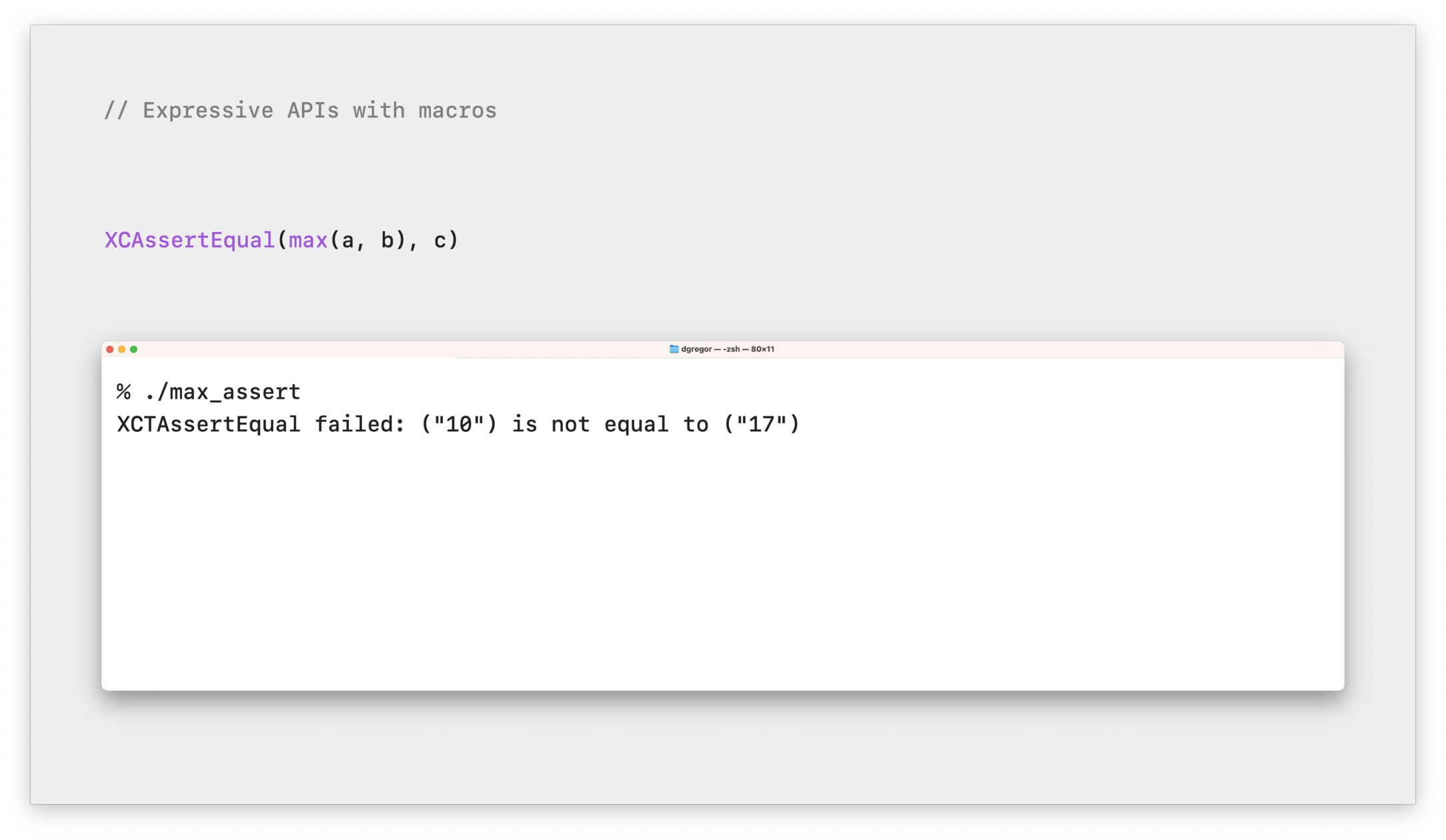
所以我们应该怎么扩展错误信息呢?在 Macro 特性推出之前,也许我们没有更好的方法。下面我们来看看如何用 Macro 特性来改善这一痛点。首先我们使用新的 hash(#) 的关键字来重写这段代码。
#assert(max(a, b) == c)
或许你会觉得这个写法很熟悉,因为 Swift 中已经有很多类似的关键字,例如 #file、#selector(...) 、#warning 的语法。当我们断言失败后,则会使用文本符号来展示一个更加详尽的图,例如这样:
如果我们想自己定义一个这种带有 # 符号的 Macro 要如何定义呢?
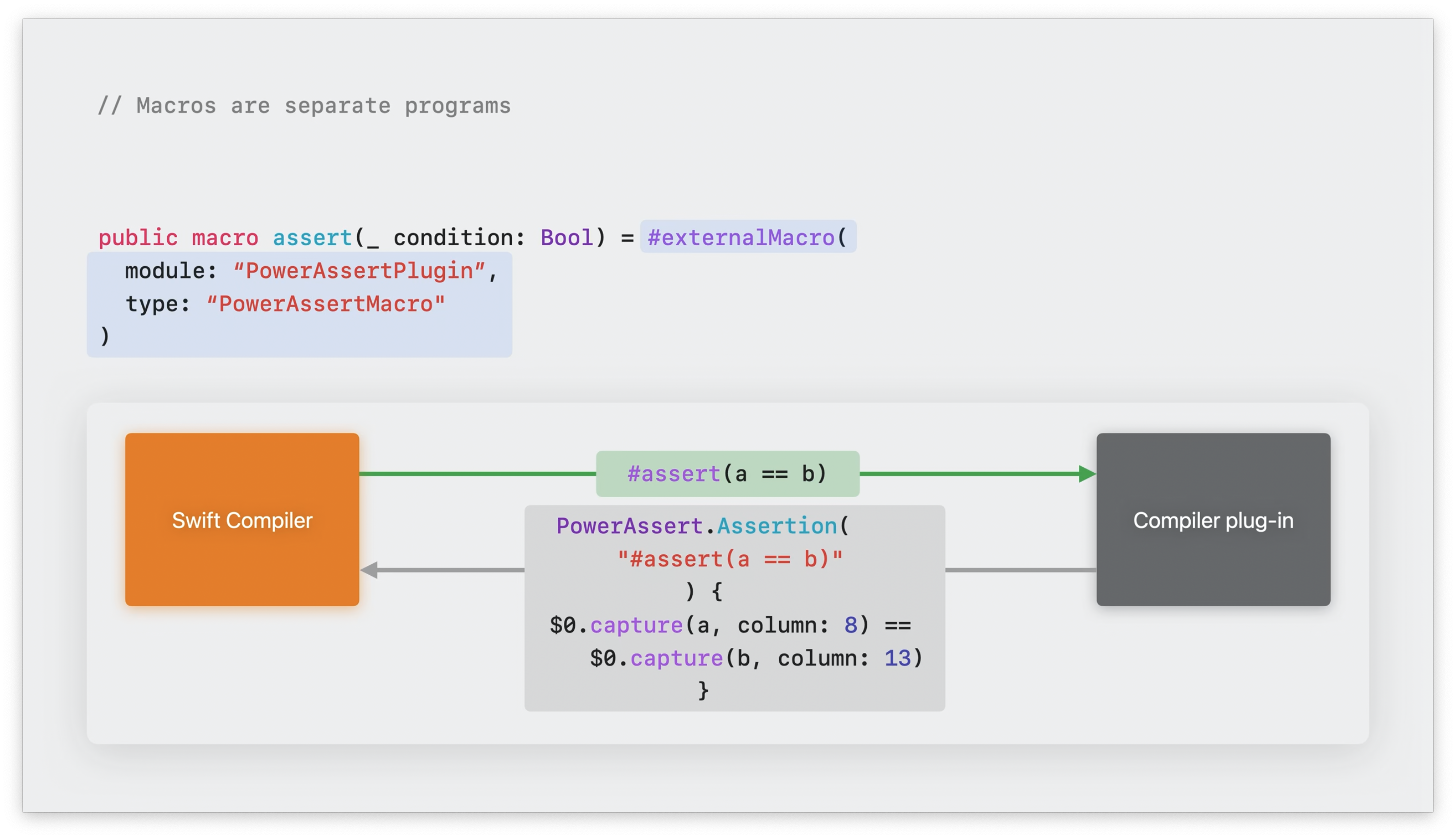
我们可以使用 macro 关键字来声明一个 Macro:
@freestanding(expression)
public macro assert(_ condition: Bool) = #externalMacro(
module: "PowerAssertPlugin",
type: "PowerAssertMacro"
)
大多数的 Macro 被定义为 External Macro,这些 External Macro 会在编译器插件的独立程序中被定义。Swift 编译器将使用 Macro 的代码传递给插件,插件产生替换后的代码,并整合回 Swift 程序中。此处,Macro 将 #assert 扩展成可以展示每个值的代码,其工作流程如下图:
Expression Macro
以上介绍的 #assert 这个 Macro 还是一个独立表达式。我们之所以称之为“独立”,是因为它使用的是 # 这个关键字作为前缀调用的一种类型。这种类型是使用 @freestanding(expression) 进行声明的。这种表达式 Macro ,可以作为一个指定类型的 Value,放在对应的位置,编译器也会更加友好地检测它的类型。
在最新版本的 Foundation 中,Predicate API 提供了一个表达式 Macro 的极好的例子。Predicate Macro 允许你使用闭包的方式,并且会对类型安全进行校验。这种可读性很强,我们看下面的示例代码,一探便知:
let pred = #Predicate<Person> {
$0.favoriteColor == .blue
}
let blueLovers = people.filter(pred)
在 Predicate Macro 中,输入的类型是一个 Type Parameter Pack Expansion,这也就是它为什么能接受任意类型、任意数量的闭包入参。而返回值是一个 Bool类型的值。在使用上,我们发现它仍旧使用 # 符号的 Hashtag 方式,所以依旧是一个表达式 Macro。我们可以来看看它的定义代码:
@freestanding(expression)
public macro Predicate<each Input>(
_ body: (repeat each Input) -> Bool
) -> Predicate<repeat each Input>
从定义上我们可以看到,这里很巧妙地用到了 Type Parameter Pack 这个特性,并且其返回值是一个 Predicate 类型的实例,从而可以实现多处复用的 Predicate 范式定义。
Attached Macro
除了这种表达式 Macro,我们还有大量的代码,需要我们对输入的参数,做出自定义的修改或者增加条件限制,显然没有输入参数的表达式 Macro 无法应对这种场景。此时,我们引入其他的 Macro,来帮助我们按照要求生成模版代码。
我们举个例子,例如在开发中,我们需要使用 Path 枚举类型,它可以标记一个路径是绝对路径还是相对路径。此时我们可能会遇到一个需求:从一个集合中,筛选出所有的绝对路径。例如如下代码:
enum Path {
case relative(String)
case absolute(String)
}
let absPaths = paths.filter { $0.isAbsolute }
extension Path {
var isAbsolute: Bool {
if case .absolute = self { true }
else { false }
}
var isRelative: Bool {
if case .relative = self { true }
else { false }
}
}
我们会发现,对于 enum 中的每一个 case 我们都需要写一个这种 isCaseX 的方法,从而增加一个过滤方法。此处是 Path 只有两种类型,但是如果在 case 更多的场景,这是一个相当繁琐的工作,而且一旦新增会带来很大的代码改动。
此处,我们可以引入 Attached Macro ,来生成繁琐的重复代码。使用后的代码如下:
@CaseDetection
enum Path {
case relative(String)
case absolute(String)
}
let absPaths = paths.filter { $0.isAbsolute }
此处的 @CaseDetection 是我们自定义的一个 Attached Macro,这个 Macro 的标志是使用和 Property Wrappers 特性中相同的 @ 符号作为语法关键字,然后将其加到你需要添加的代码前方进行使用。它会根据你对于 Attached Macro 的实现,来生成代码,从而满足需求。
在上面这个例子中,我们的作用范围是 Path 这个 enum 类型的每一个 Member ,所以在使用的时候,表达是 @attached(member)。Attached Macro 提供 5 种作用范围给开发者使用:
| Attached Macro 类型 | 作用范围 |
|---|---|
@attached(member) |
为类型/扩展添加声明(Declaration) |
@attached(peer) |
为声明添加新的声明 |
@attached(accessor) |
为存储属性添加访问方法(set/get/willSet/didSet) |
@attached(memberAttribute) |
为类型/扩展添加注解(Attributes)声明 |
@attached(conformance) |
为类型/扩展添加遵循的协议 |
通过这些 Attached Macro 的组合使用,可以达到很好的效果。这里最重要的例子就是我们在 SwiftUI 中经常使用到的 observation 特性。
通过 observation 特性,我们可以观察到 class 中的 Property 的变化。想要使用这个功能,只需要让类型遵循 ObservableObject 协议,将每个属性标记为 @Published ,最后在 View 中使用 ObservedObject 的 Property Wrapper 即可。我们来写个示例代码:
// Observation in SwiftUI
final class Person: ObservableObject {
@Published var name: String
@Published var age: Int
@Published var isFavorite: Bool
}
struct ContentView: View {
@ObservedObject var person: Person
var body: some View {
Text("Hello, \(person.name)")
}
}
我们会发现以上的 3 步,会有很多繁琐且复杂的工作需要我们手工处理。如果我们忘记了一步,就无法完成观察 Property 变化、自动触发 UI 刷新这样的需求。
当我们有了 Attached Macro 之后,我们就可以简化声明过程。例如我们有一个 @Observable 的 Macro ,可以完成以上操作。则我们的代码就可以精简成这样:
// Observation in SwiftUI
@Observable final class Person {
var name: String
var age: Int
var isFavorite: Bool
}
struct ContentView: View {
var person: Person
var body: some View {
Text("Hello, \(person.name)")
}
}
我们发现我们的代码得到了极大的精简,这得益于我们组合使用 Attached Macro 的效果。在 Macro 声明部分的代码如下:
@attached(member, names: ...)
@attached(memberAttribute)
@attached(conformance)
public macro Observable() = #externalMacro(...).
下面我们来深入探究一下每一个 Attached Macro 的作用。
以下是关键代码:
@Observable final class Person {
var name: String
var age: Int
var isFavorite: Bool
}
首先,Member Macro 会引入新的属性和方法,编译器将 Macro 代码替换后将变成这样:
@Observable final class Person {
var name: String
var age: Int
var isFavorite: Bool
// 这里定义了一个 `ObservationRegistrar` 实例,
// 用于管理观察事件的实例,当属性发生变化将通知所有 Observer
internal let _$observationRegistrar = ObservationRegistrar<Person>()
// access 方法会在属性被访问时调用,通过 ObservationRegistrar 的 access
// 方法,并传入被访问的属性 keyPath,来触发事件
internal func access<Member>(
keyPath: KeyPath<Person, Member>
) {
_$observationRegistrar.access(self, keyPath: keyPath)
}
// withMutation 方法用于在修改属性时触发观察方法。在修改属性之前和之后分别触发观察事件,
// 以便于观察者可以检测到属性的变化。这个方法通过 `ObservationRegistrar` 的 `withMutation`
// 方法,传入被修改的属性的 keyPath 和一个闭包,这个闭包包含了对属性的修改操作
internal func withMutation<Member, T>(
keyPath: KeyPath<Person, Member>,
_ mutation: () throws -> T
) rethrows -> T {
try _$observationRegistrar.withMutation(of: self, keyPath: keyPath, mutation)
}
}
其次,Member Attribute Macro 会为所有的属性添加 @ObservationTracked ,这个 Property Wrapper 会为属性添加 get 和 set 方法。
最后,Conformance Macro 会让 Person 这个 class 遵循 Observable协议。
通过这三个宏的改造,编译器将代码进行展开后,我们的真实代码类似以下:
@Observable final class Person: ObservableObject {
@ObservationTracked var name: String { get { … } set { … } }
@ObservationTracked var age: Int { get { … } set { … } }
@ObservationTracked var isFavorite: Bool { get { … } set { … } }
internal let _$observationRegistrar = ObservationRegistrar<Person>()
internal func access<Member>(
keyPath: KeyPath<Person, Member>
) {
_$observationRegistrar.access(self, keyPath: keyPath)
}
internal func withMutation<Member, T>(
keyPath: KeyPath<Person, Member>,
_ mutation: () throws -> T
) rethrows -> T {
try _$observationRegistrar.withMutation(of: self, keyPath: keyPath, mutation)
}
}
虽然展开后的代码十分复杂,但是绝大多数代码都被 @Observable Macro 封装起来了,我们只需要输入以下的简洁版本即可实现。
@Observable final class Person {
var name: String
var age: Int
var isFavorite: Bool
}
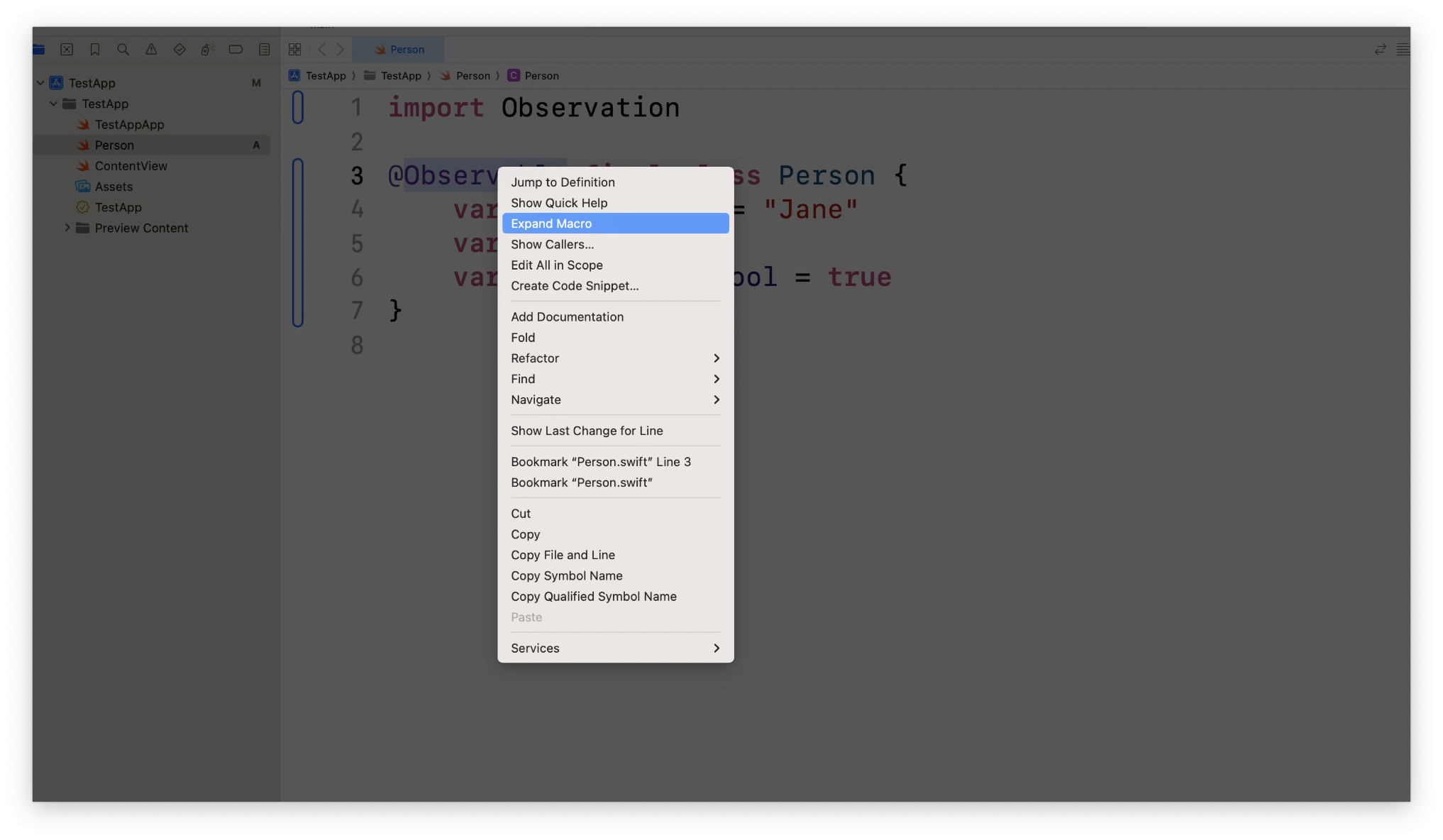
当你需要对 Macro 展开,希望更好地理解程序代码时,你可以使用 Xcode 的 Expand Macro 功能对 Macro 进行源代码展开。任何在 Macro 生成的代码中出现的错误消息都会引导你去展开代码,从而快速地发现问题。
Swift Macro 为 Swift 实现更具可读性的 API 、构建更简洁的实现语法提供了一种新的模式。Macro 可以根据我们的需求,批量生成 Swift 代码,并在程序中使用 @ 或者 # 语法快速引入,简化了业务代码,也提高了可读性。
本文只是对 Swift Macro 进行一个初步的介绍以便于你从零到一认识。如果想学习更多,可以查看《Write Swift Macro》这个 Session ,通过实践来编写自己的 Swift Macro。另外如果想对 Swift Macro 的设计理念有更深刻的了解,可以学习《Expand on Swift》 这个 Session。
Swift Foundation 升级
Swift 这门编程语言的定位是一种可扩展的语言,其设计理念是使用清晰、简洁的代码,方便阅读和编写。其中的一些强大的特性,例如泛型、async/await 支持等等,可以支撑像 SwiftUI 或 SwiftData 这种更贴近自然描述的框架,从而允许开发者将关注点聚焦在业务上。
为了实现更加宽泛的可扩展性,我们需要将 Swift 适配较于 Objective-C 更多的领域,其中也包括更底层的操作系统领域,这一部分之前是由 C 或 C++ 进行编写的。
最近我们在 Swift 社区中,开源了 Foundation 的 Swift 重构版本,这个措施将使 Apple 以外的平台也可以享受到 Swift 带来的更加高效的性能和开发优势。但是也以为着我们需要用 Swift 对大量的 Objective-C 和 C 代码进行重构。
截止至 macOS Sonoma 和 iOS 17,一些基本类型已经完成了 Swift 重构版本,例如 Date、Calendar、Locale 和 AttributedString。另外 Swift 实现的 Encoder 和 Decoder 性能相较旧版本也有所提升。
下图是我们通过跑这些类库 Benchmark 测试用例,所得出的 Swift 重构版本的性能提升数据:

这些性能提升除了得益于 Swift 整体工具链的性能,另外还有一个原因就是 macOS Sonoma 系统上,我们避免了语言调用时的桥接成本(Bridging Cost),不需要再调用 Objective-C 的代码。我们从 enumerateDates 这个方法的调用数据统计中可以看到这个变化:

Ownership & Non-copyable Type
在对 Foundation 进行重构时,有时在操作系统的底层操作中,为了达到更高的性能水平,需要更细粒度的掌控。Swift 5.9 引入了“所有权”(Ownership)的概念,用来描述在你的代码中,当值在传递时,是哪段代码在“拥有”该值。
也许这个 Ownership 用文字描述起来有一些抽象,我们来看下示例:
struct FileDescriptor {
private var fd: CInt
// 初始化方法,接受文件描述符作为参数
init(descriptor: CInt) {
self.fd = descriptor
}
// 写入方法,接受一个 UInt8 数组作为缓冲区,并抛出可能的错误
func write(buffer: [UInt8]) throws {
let written = buffer.withUnsafeBufferPointer {
// 使用 Darwin.write 函数将缓冲区的内容写入文件描述符,并返回写入的字节数
Darwin.write(fd, $0.baseAddress, $0.count)
}
// ...
}
// 关闭方法,关闭文件描述符
func close() {
Darwin.close(fd)
}
}
这是一段 FileDescriptor 的封装代码,我们可以用它更加方便的进行写文件操作。但是在使用的时候我们会经常犯一些错误,例如:你可能会在调用 close() 方法后,再执行 write(buffer:)方法。再比如:你可能会在 write(buffer:) 方法后,忘记调用 close()方法。
对于上面说的第二个场景,我们可以将 struct 修改成 class,通过在 deinit 方法中,调用 close() 方法,以便于在示例释放的时候,自动关闭。
class FileDescriptor {
// ...
deinit {
self.close(fd)
}
}
但是这种做法也有它的缺点,例如它会造成额外的内存分配。虽然在通常情况下并不是大问题,但是在操作系统代码中某些受限的场景下是一个问题。
另外,class 构造出的示例,传递的都是引用。如果这个 FileDescriptor 在多个线程之间得到访问,导致竞态条件,或者持久化了这个实例导致引用计数始终大于 0 ,内存无法释放,进而引发内存泄漏。
再让我们重新回顾一下之前的 struct 版本。其实这个 struct 的行为也类似于引用类型。它会持有一个 fd 的整数,这个整数就好比引用了一个文件状态值,我们可以理解成打开了一个文件。如果我们复制了一个实例,相当于我们延长了这个文件的打开状态,如果后续代码中无意对其操作,这是不符合我们预期的。
Swift 的类型,无论是 struct 还是 class ,默认都是 Copyable 的。在大多数情况下,不会产生任何问题。但是有的时候,隐式复制的编译器行为,并不是我们希望的结果,尤其是在受限场景下,内存分配是我们要重点关注的问题。在 Swift 5.9 中,可以使用新的语法来强制声明禁止对类型进行隐式复制。当类型不能复制时,则可以像 class 一样提供一个 deinit 方法,在类型的值超出作用域时执行该方法。
struct FileDescriptor: ~Copyable {
private var fd: CInt
init(descriptor: CInt) { self.fd = descriptor }
func write(buffer: [UInt8]) throws {
let written = buffer.withUnsafeBufferPointer {
Darwin.write(fd, $0.baseAddress, $0.count)
}
// ...
}
consuming func close() {
Darwin.close(fd)
}
deinit {
Darwin.close(fd)
}
}
像 FileDescriptor 这样被声明为 ~Copyable 的类型,我们称之为 Non-copyable types 。我们通过这样声明可以解决之前提出的第一个场景。
这里的 close 操作,其实就相当于上下文已经放弃了这个实例的 Ownership,这也就是上面代码中 consuming 关键字的含义。当我们将方法标注为 consuming 后,就同时声明了 Ownership 的放弃操作,也就意味着在调用上下文中,后文将无法使用该值。
当我们按照这个写法,在实际业务代码中使用的时候,我们会按照这样的执行顺序进行操作:
let file = FileDescriptor(fd: descriptor)
file.write(buffer: data)
file.close()
因为 close 操作被我们标记了是 consuming 方法,则它必须在最后调用,以确保在此之前上下文代码具有该实例的 Ownership。如果我们写出了错误的调用顺序,编译器将会报错,并提示我们已经放弃了 Ownership ,无法继续调用其他方法。

Non-copyable Type 是 Swift 针对系统编程领域的一项强大的新功能,但目前仍处在早期阶段,后续版本将会不断迭代和扩展 Non-copyable Type 的功能。
与 C++ 的互操作性
混编代码
Swift 的推广普及其中一个重要的原因就是和 Objective-C 的互操作性。从一开始,开发者就可以使用 Swift 和 Objective-C 混编的方式,在项目中逐渐将代码替换成 Swift。
但是我们了解到,在很多项目中,不仅用到了 Objective-C,而且还用到了 C++ 来编写核心业务,互操作接口的编写比较麻烦。通常情况下,需要手动添加 bridge 层,Swift 经过 Objective-C ,再调用 C++ ,得到返回值后,再反向传出,这是一个十分繁琐的过程。
Swift 5.9 引入了 Swift 与 C++ 的互操作能力特性,Swift 会将 C++ 的 API 映射成 Swift API ,从而方便调用和获得返回值。
C++ 是一个功能强大的语言,具有自己的类、方法、容器等诸多概念。Swift 编译器能够识别 C++ 常见的习惯用法,因此大多数类型可以直接使用。例如下面这个 Person 类型,定义了 C++ 类型中常见的五个成员函数:拷贝构造函数、转移(有些中文教材也叫做移动)构造函数、(两个)赋值重载运算符、析构函数。
// Person.h
struct Person {
// 拷贝构造函数: 通过从另一个Person对象进行拷贝来构造新的Person对象
Person(const Person &);
// 转移构造函数: 通过从另一个Person对象进行移动来构造新的Person对象
Person(Person &&);
// 拷贝赋值重载运算符: 将另一个Person对象的值赋给当前对象
Person &operator=(const Person &);
// 转移赋值重载运算符: 通过移动另一个Person对象的值来赋给当前对象
Person &operator=(Person &&);
// 析构函数: 清理Person对象所持有的资源
~Person();
// string 类型,存储人员姓名
std::string name;
// const 代表只读,用于返回人员年龄
unsigned getAge() const;
};
// 函数声明,返回一个 Person 对象的 vector 容器
std::vector<Person> everyone();
我们通过 Swift 可以直接调用这个 C++ 的 struct ,也可以直接使用上面定义的 vector<Person> 。补充一句:C++ 的常规容器,例如:vector、map 等,Swift 均是可以直接访问的。
// Client.swift
func greetAdults() {
for person in everyone().filter { $0.getAge() >= 18 } {
print("Hello, \(person.name)!")
}
}
正如 greetAdults() 方法描述的这样,我们在 Swift 中可以直接调用 C++ 定义的类型,从而达到和 C++ 的优秀交互能力。
下面来说说“反向”用 C++ 调用 Swift 的场景。C++ 中使用 Swift 的代码基于与 Objective-C 相同的机制,即编译器会自动生成一个 Header 文件,我们可以在 Xcode 中找到生成后的 C++ header。然而与 Objective-C 不同的是,你不需要使用 @objc 这个注释对方法进行标注。C++ 大多数情况下是可以使用 Swift 完整的 API,包括属性、方法和初始化方法,无需任何桥接成本。
举个例子:
// Geometry.swift
struct LabeledPoint {
var x = 0.0, y = 0.0
var label: String = "origin"
mutating func moveBy(x deltaX: Double, y deltaY: Double) { … }
var magnitude: Double { … }
}
这是一个 Swift 定义的 struct ,下面我们在 C++ 文件中来使用它:
// C++ client
#include <Geometry-Swift.h>
void test() {
Point origin = Point()
Point unit = Point::init(1.0, 1.0, "unit")
unit.moveBy(2, -2)
std::cout << unit.label << " moved to " << unit.magnitude() << std::endl;
}
我们可以看到,在遵循 C++ 语法习惯的前提下,所有的方法名都没有发生变化,无需对 Swift 代码进行定制化修改即可完成调用。
Swift 的 C++ 交互让大家在业务开发中更加容易。许多 C++ 习惯用法可以直接在 Swift 中表达,通常是自动完成的,但偶尔需要一些标记(annotation)来指示所需的语义。而且,可以直接从 C++ 访问 Swift API,无需注释或更改代码,提升了开发效率,也降低了迁移成本。
有些地方会将 annotation 翻译成“注释”,但是校对者 stevapple 在此处建议使用标记进行翻译,因为是用作编译器来声明额外的语义操作。个人也比较采纳。
C++ 的交互也是一个不断迭代的 feature,如果想了解更多,可以参看《Mix Swift and C++》这个 session。
构建系统
与 C++ 的交互在语言层面上十分重要,但是我们也不能忽视构建系统的适配。因为使用 Xcode 和 Swift Package Manager 来替换 C++ 的整套构建系统,也是开发者的一个障碍。
这也就是为什么我们要将这个 topic 单独拿出来讨论。Swift 与 CMake 开发社区合作改进了 CMake 对 Swift 的支持。你可以将 Swift 声明为项目使用的一种语言,并将 Swift 源文件加入 target 中,从而将 Swift 代码集成到 CMake 构建中。
# CMake
project(PingPong LANGUAGES CXX Swift)
add_library(PingPong
Ping.swift,
Pong.swift,
TableTennisUtils.cpp
)
值得一提的是,你也可以在单个 Target 中混合使用 C++ 和 Swift ,CMake 将确保分别编译每个语言,并链接适用于两种语言适当的系统库和 Runtime 库。这也就意味着,你可以使用 Swift 来逐步取代跨平台的 C++ 项目。另外,Swift 社区还提供了一个包含 Swift 和混合 C++/Swift Target 的 CMake 实例存储库,其中包括使用桥接和生成的头文件,来帮助你上手。
Swift Concurrency - Actor 执行器
几年前,我们引入了基于 async/await 、Structured Concurrency 以及 actors 构建的并发模型。Swift 的并发模型是一个通用抽象模型,可以适配不同的环境和库。在这个通用抽象模型中有两个主要部分,Tasks 和 Actors:
- Tasks:代表可以在任意位置顺序执行的逻辑。如果有
await关键字,tasks 可以被挂起,等其执行完成后继续恢复执行; - Actors:是一种同步机制,提供对隔离状态的互斥访问权。从外部进入一个 actor 需要进行
await,否则当前可能会将 tasks 挂起。
在内部实现上,Tasks 在全局并发池(Global Concurrent Pool)上执行。全局并发池根据环境决定如何调度任务。在 Apple 平台中,Dispatch 类库为每个系统提供了针对性优化的调度策略。
但是和前文问题一样,我们考虑更受限的环境下,多线程调度的开销我们无法接受。在这种情况下,Swift 的并发模型则会采用单线程的协同队列(Single-threaded Cooperative Queue)进行工作。同样的代码在多种情况下都可以正常工作,因为通用抽象模型可以描述的场景很广,可以覆盖到更多 case。
在标准的 Swift 并发运行场景下, Actors 是通过无锁任务队列(Lock-free Queue of Tasks)来实现的,但这不是唯一的实现方式。在受限环境下,没有原子操作(Atomics),可以使用其他的并发原语(Concurrency Primitive),比如自旋锁。如果考虑单线程环境,则不需要同步机制,但 Actors 模型仍然可被通用模型覆盖到。如此你可以在单线程和多线程环境中,使用同一份代码。
在 Swift 5.9 中,自定义 Actor 执行器(Executors)允许实现特定的同步机制,这使 Actors 变得更加灵活。我们来看一个例子:
// Custom actor executors
// 定义一个名为MyConnection的actor类,用于管理数据库连接
actor MyConnection {
private var database: UnsafeMutablePointer<sqlite3>
// 初始化方法,接收一个文件名作为参数,并抛出异常
init(filename: String) throws { … }
// 用于清理旧条目的方法
func pruneOldEntries() { … }
// 根据给定的名称和类型,从数据库中获取一个条目
func fetchEntry<Entry>(named: String, type: Entry.Type) -> Entry? { … }
}
// 在外部调用时使用"await"来暂停当前任务,等待pruneOldEntries方法完成
await connection.pruneOldEntries()
这是一个管理数据库连接的 Actor 例子。Swift 确保代码对 Actor 互斥访问,所以不会出现对数据库的并发访问。但是如果你需要对同步访问进行控制要如何做呢?例如,当你连接数据库的时候,你想在某个队列上执行,而不是一个未知的、未与其他线程共享的队列。在 Swift 5.9 中,可以自定义 actor 执行器,可以这样实现:
actor MyConnection {
private var database: UnsafeMutablePointer<sqlite3>
// 执行方法的队列
private let queue: DispatchSerialQueue
// 这里自定义 actor 的执行器,nonisolated 定义为它是一个非孤立方法,即不需要在外部使用 await 关键字
nonisolated var unownedExecutor: UnownedSerialExecutor { queue.asUnownedSerialExecutor() }
init(filename: String, queue: DispatchSerialQueue) throws { … }
func pruneOldEntries() { … }
func fetchEntry<Entry>(named: String, type: Entry.Type) -> Entry? { … }
}
await connection.pruneOldEntries()
上述代码中,我们为 actor 添加了一个串行调度队列,并且提供了一个 unownedExecutor 的实现,用于生成与该队列关联的执行器。通过这个改变,所有 actor 实例的同步方法将通过这个队列来执行。
当你在外部调用 await connection.pruneOldEntries() 时,其实现在真正的行为是在上方的队列里调用了 dispatchQueue.async 。有了这个自定义执行器后,我们可以全方位控制 Actor 的方法调度,甚至可以与未使用 Actor 的方法混用并调度他们的执行顺序。
我们可以通过调度队列对 actor 进行同步调度,是因为调度队列遵循了新的 SerialExecutor 协议。开发者可以通过实现一个符合该协议的类,从而定义自己的调度机制。
// Executor protocols
protocol Executor: AnyObject, Sendable {
// 方法 1
func enqueue(_ job: consuming ExecutorJob)
}
protocol SerialExecutor: Executor {
// 方法 2:
func asUnownedSerialExecutor() -> UnownedSerialExecutor
// 方法 3:
func isSameExclusiveExecutionContext(other executor: Self) -> Bool
}
extension DispatchSerialQueue: SerialExecutor { … }
在这个协议中包括了一些核心操作:
- 检查代码是否已经在执行器上下文中执行:如上代码中的方法 3
isSameExclusiveExecutionContext(other:)。例如:你可以实现是否在主线程上执行。 - 可以获取这个 Executor 对应的执行器实例,并访问它:如上代码中的方法 2
asUnownedSerialExecutor()。 - 将某个 Job 的所有权给到这个执行器:如上述代码中的方法 1
enqueue(_:)。
Job 是需要在执行器上同步完成异步任务,这样的一个概念。从运行表现上来说,还是列举上面数据库连接的例子,enqueue方法将会在我们声明的队列上,调用 dispatchQueue.async 方法。
Swift 并发编程目前已经有了几年的经验,Tasks 和 Actor 这套模型也覆盖了诸多并发场景。从 iPhone 到 Apple Watch ,再到 Server ,其已适应不同的执行环境。这是一套复杂却又实用的系统,如果你希望了解更多,可以查看《Behind the Scenes》和《Beyond the basics of Structured Concurrency》这两个 Session。
FoundationDB
最后我们介绍一点额外的东西,FoundationDB。这是一个分布式数据库,用于在普通硬件上运行的可扩展数据库解决方案。目前已经支持 macOS 、Linux 和 Windows。
FoundationDB 是一个开源项目,代码量很大,且使用 C++ 编写。这些代码是强异步的,具有自己的分布式 Actor 和 Runtime 实现。FoundationDB 项目希望对其代码进行现代化改造,并且认为 Swift 在性能、安全性和代码可读性上与其需求十分匹配。但是完全使用 Swift 重构是一个非常冒险的任务,所以在最新版代码中,开发人员利用 Swift 与 C++ 的交互新特性,进行部分的重构。
首先我们来看一下 FoundationDB 部分的 Actor 代码片段 C++ 实现:
// FoundationDB的“master data” actor的C++实现
// 异步函数,用于获取版本号
ACTOR Future<Void> getVersion(Reference<MasterData> self, GetCommitVersionRequest req) {
// 查找请求代理的迭代器
state std::map<UID, CommitProxyVersionReplies>::iterator proxyItr = self->lastCommitProxyVersionReplies.find(req.requestingProxy);
++self->getCommitVersionRequests;
// 如果在映射中找不到代理的迭代器,则发送一个“Never”的响应并返回
if (proxyItr == self->lastCommitProxyVersionReplies.end()) {
req.reply.send(Never());
return Void();
}
// 等待直到最新的请求编号至少达到 req.requestNum - 1
wait(proxyItr->second.latestRequestNum.whenAtLeast(req.requestNum - 1));
// 在回复的映射中查找与请求编号对应的回复
auto itr = proxyItr->second.replies.find(req.requestNum);
if (itr != proxyItr->second.replies.end()) {
// 如果找到回复,则将其作为响应发送并返回
req.reply.send(itr->second);
return Void();
}
// ...
}
这段代码有很多内容,你并不需要了解这段 C++ 代码。其中,我只想指出一个关键的地方:因为 C++ 没有 async/await ,所以 FoundationDB 使用了类似于预处理器(Preprocessor)的方式进行模拟实现。
通过对应的编号进行筛选,从而显式实现了消息匹配,从而将正确的结果返回。最后,FoundationDB 有自己的引用计数智能指针来帮助自动管理内存。上述 C++ 代码描述的就是这样的一个过程。
但如果我们使用 Swift ,这个方法就可以直接使用异步函数的特性,使用 await 来表示对于请求的匹配,就节省了上述大量的代码逻辑。
// FoundationDB的“master data” actor的Swift实现
// 异步函数,用于获取版本号
func getVersion(
myself: MasterData, req: GetCommitVersionRequest
) async -> GetCommitVersionReply? {
// 增加getCommitVersionRequests计数
myself.getCommitVersionRequests += 1
// 检查是否存在请求代理的最后版本回复
guard let lastVersionReplies = lastCommitProxyVersionReplies[req.requestingProxy] else {
return nil
}
// ...
// 等待直到latestRequestNum至少达到req.requestNum - 1
var latestRequestNum = try await lastVersionReplies.latestRequestNum
.atLeast(VersionMetricHandle.ValueType(req.requestNum - UInt64(1)))
// 如果存在请求编号对应的最后回复,则返回该回复
if let lastReply = lastVersionReplies.replies[req.requestNum] {
return lastReply
}
}
是不是可读性提高了不少?
另外,我们在这里使用了很多 C++ 类型,C++ 中的 MasterData 类型使用了引用计数智能指针。通过在 C++ 中对类型进行标注,Swift 编译器可以像任何其他类一样使用该类型,自动管理引用计数。
从这个例子中,我们获取到的经验是,我们可以在需要的时候,使用 Swift 的优势来改写逻辑,与现有的 C++ 代码进行接口互调操作,实现渐进式的代码替换,最终也可以推进项目 Swift 化的进程。
总结
这个 Session 中我们讨论了很多内容,不乏 Swift 的一些新的语法特性和 Swift Macros。这些功能可以实现更加灵活和健壮的 API,帮助你更好地编写高质量代码。
另外,我们也大篇幅的讨论了在受限环境下使用 Swift 的优势,以及 Swift 如何灵活的适配多种平台设备、语言,这些也为我们在编写代码中,获得更多的思考。
这些特性的出现和设计,都是通过 Swift 社区中从 idea 、公开讨论、结果反馈等等流程中孕育而生的。感谢各位开发者的支持,让 Swift 5.9 这门编程语言更加健壮。
