知识梳理
- 在「初识最大流问题」中,我们了解了什么是流网络模型、什么是最大流问题、以及在流网络中 的增广路(Augmenting Path)概念;
- 在「Ford-Fulkerson 最大流求解方法」中,我们学习了 Ford-Fulkerson 的最大流问题求解方法和思路:不断的深度优先搜索,直到没有增广路为止则获得最大流;
- 在「二分匹配的最大流思维」中,通过增加超级源和超级汇来修改二分图,从而将二分匹配问题转换成了最大流问题,最后通过 Ford-Fulkerson 方法解决。
以上三篇先导文章都是在认识和使用最大流这种问题模型,从而进行一些算法思考。但是我们始终没有关心 Ford-Fulkerson 方法的时间复杂度问题。
这篇文章会讲述一个求解最大流问题的 EK 算法,从而优化在某些场景下最大流问题的求解效率。
Ford-Fulkerson 方法有什么问题?
我们知道,在之前讨论的图中,根据 Ford-Fulkerson 方法,我们采用深度优先搜索(下文简称 DFS),不断的去寻找查询增广路,从而增加超级汇点的流量。先来复习一下 Ford-Fulkerson 方法的算法流程:
- 使用 DFS 搜索 出一条增广路;
- 在这条路径中所有的边的容量减去这条增广路的流量 f,并建立容量为 f 的反向边;
- 返回操作一,直到没有增广路;
在这个算法流程中,为将 “使用 DFS” 进行了加粗,你一定察觉到一些端倪。我们来从这个角度来思考一下:
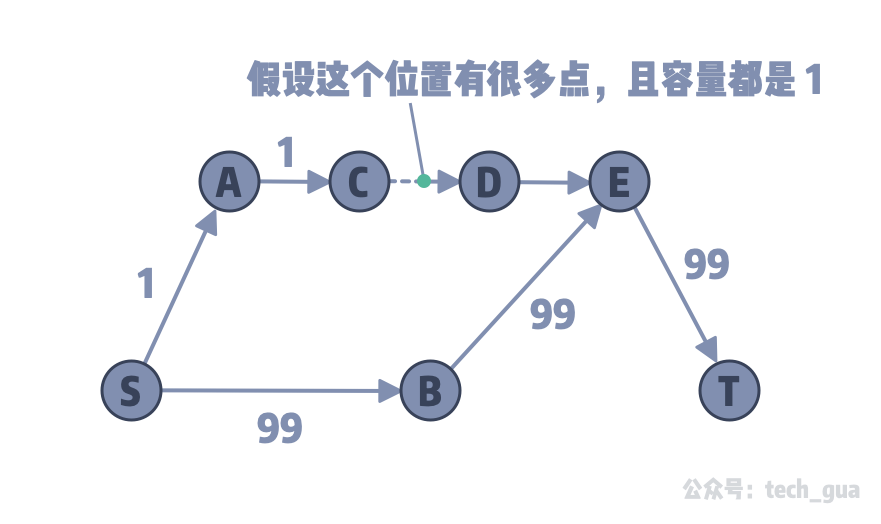
假设有一个网络流如上图所示,我们可以一眼看出最大流是 99。但是在我们代码中使用 Fold-Fulkerson 算法进行查找增广路的过程中,由于根据标号进行搜索,所以一定会先找到 S → A → C → …. → D → E → T 这条增广路。于是我们就浪费了很多开销。
其实我们在这个问题中,只要找到 S → B → E → T 这条增广路,就可以将 T 的入度达到满流状态,后续也就直接结束了。
算法导论上给出的最坏情况分析
如果有一个图,某一条边是一个“噪声边”(所谓“噪声”就是指它在最终的结果中是没有对汇点进行增广的,也就是没有贡献流量的),它的容量很少,并且它在 DFS 搜索中,位置十分靠前,每一次都优先搜到了这一条增广路,那么在每一个二次搜索增广路的时候,都会去抵消它的流量,通过反向边完成一次真实的增广操作。这样问题就十分严重了。我举一个例子:
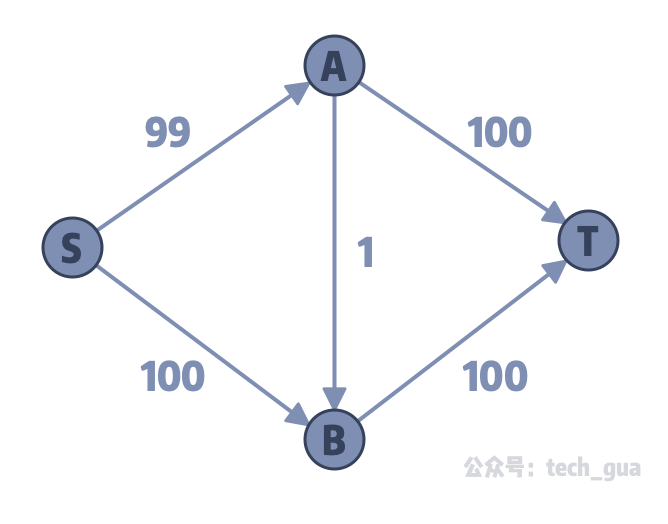
上面这个图,我们看一眼就知道它的结果是 s → 0 → t 和 s → 1 → t 这两个增广路贡献的流量和 199,但是由于 0 → 1 这条边的序号十分靠前,所以每次在进行搜索增广路的过程中,就会优先使用 S → A → B → T 这条边;然后在第二次选择增广路时,我们选择了 S → B → A → T ,如此这样反复,我们发现每一次找到增广路,只增加了 1 个单位的流量,所以如此反复 199 次才能完成最大流算法的计算。
我们用动图来描述一下这个场景:
结合代码,我们来看看到底进行了多少次的增广操作:
#include <iostream>
#include <vector>
#include <queue>
#include <unordered_map>
using namespace std;
#define INF 0x3f3f3f3f
const int MAX_V = 1e4 + 5;
struct Edge {
int to, cap, rev;
Edge(int _to, int _cap, int _rev): to(_to), cap(_cap), rev(_rev) {}
};
// 邻接表记录点和其相连的边
// 比如节点 1 的所有出度边集 G[1]
vector<Edge> G[MAX_V];
void add_edge(int from, int to, int cap) {
G[from].push_back(Edge(to, cap, G[to].size()));
G[to].push_back(Edge(from, 0, G[from].size() - 1));
}
bool used[MAX_V];
int dfs(int c, int t, int f) {
if (c == t) {
return f;
}
used[c] = true;
for (int i = 0; i < G[c].size(); ++ i) {
Edge &e = G[c][i];
if (!used[e.to] && e.cap > 0) {
int d = dfs(e.to, t, min(f, e.cap));
if (d > 0) {
e.cap -= d;
G[e.to][e.rev].cap += d;
return d;
}
}
}
return 0;
}
int max_flow(int s, int t) {
int flow = 0;
int cnt = 0;
for (;;) {
memset(used, 0, sizeof(used));
int f = dfs(s, t, INF);
cnt += 1;
if (f == 0) {
cout << cnt << endl; // 5 - 也就是说只进行了 5 次增广路查询
return flow;
}
flow += f;
}
}
int main() {
// 0: S点
// 1: A点
// 2: B点
// 3: T点
add_edge(0, 1, 99);
add_edge(0, 2, 100);
add_edge(1, 2, 1);
add_edge(1, 3, 100);
add_edge(2, 3, 100);
int ret = max_flow(0, 3);
cout << ret << endl; // 199
}
但我们发现,即使先搜索了 S → A → B → T 这条增广路,也不会出现这种最坏情况。原因是因为我们所实现的 Ford-Fulkerson 方法是使用 DFS 深度优先搜索查找增广路,在实现中有这句:
int d = dfs(e.to, t, min(f, e.cap));
这个 DFS 中会有回溯流程,也就是说,当我们找到 S → A → B → T 之后,对所有边的容量减 1 ,此时回溯到了 A 点,则又会继续查找 S → A → T 这条增广路。所以我们并不能看到《算法导论》中讨论的这种最差情况。
虽然这种极限情况是无法得到的,但是我们也知道了传统的 Ford-Fulkerson 方法还是存在优化的可能。
基于 DFS 的 FF 方法复杂度分析
从上面这里例子,你已经发现了,当基于 DFS 的 FF 算法的最差情况复杂度是和最大流相关的。假设我们有 E 条边并且最大流是 F,每次 DFS 查增广路则需要 O(E) 的复杂度,当最大流是 E 的时候,我们要进行最多 E 次的增广路查找。
所以基于 DFS 的 FF 算法的时间复杂度是:
\[O(V·F)\]但是由于我们使用的是带有回溯的 DFS ,所以复杂度是要小于上述这个结果的。这个结果就是 Ford-Fulkerson 方法的算法复杂度上届。
Edmond-Karp 算法解析
再回头看这个图,我们能得到什么启发呢?
启发就是,如果我们能够尽早的找到 S → B → E → T 这条增广路是不是就可以了?
沿着这个思路我们继续思考,是不是有一种搜索方式可以均衡分配到每一个搜索结果中相同的层级呢?是的,就是 BFS 广度优先搜索。是的,计算机科学家 Edmond-Karp 也是这么考虑的。
我们再用《算法导论》中的流网络,配合 BFS 广度优先搜索,进行增广路的查找来看一下在 Edmond-Karp 最大流的代码实现中我们需要记录哪些信息?
在 Edmond-Karp 最大流算法中,可以看到总流程也是分成 3 步:
- 使用 BFS 找到一条增广路(对应下面的步骤 1);
- 计算这条路的最小容量边,为汇点加流量,并建立反向边,其容量为增加的流量(对应下面的步骤 2);
- 重复第一步,如果不能找到一条增广路则得到最大流;
但是在实现上,由于我们采用了 BFS 方法,则无法对这条增广路进行回溯处理。所以在代码实现的时候,我们需要通过一个数组或者一个 Map 来记录下对应点在增广路上的入度边。
下面我们来拆解这几步的实现单独来看。
1. BFS 搜索查询增广路
为了解释 BFS 的查询方式,我又画了一个不规则的流网络来简书 BFS 查询最短路的流程:

从这个过程中可以看出,我们从源点 S 进行 BFS 广度优先搜索,当第一次到达汇点 T 后就停止搜索,然后来执行我们的增加流量和建立反向边的操作。由于我们需要在到达汇点 T 后来处理这条路径,所以需要一个数组或者 Map 记录每一个节点的入度边,这样也就可以从后向前获取到这条路径了。
// 用来记录当前路径上的最小容量,用于加流量操作
int a[MAX_V];
// 记录下标点的边编号,pair 对应 G[x1][x2],x1 是描述哪个入度点,x2 是描述 x1 点的第 x2 条边
unordered_map<int, pair<int, int>> pre;
我们确定了要记录哪些信息,剩下的就是 BFS 流程了:
void bfs(int s, int t) {
// a 初始化成 0,也可以判断是否已经被染色,从而剪枝情况
memset(a, 0, sizeof(a));
// 使用队列,保存处理节点
queue<int> que;
que.push(s);
// 每个节点所流过的流量设置为 INF 无穷大
// 这样可以起到求最小的作用
a[s] = INF;
while (!que.empty()) {
int x = que.front();
que.pop();
// 遍历当前节点的所有边
for (int i = 0; i < G[x].size(); ++ i) {
Edge& e = G[x][i];
// 如果相连的点没有访问,并且这条边的容量大于 0
if (!a[e.to] && e.cap > 0) {
// 记录下一个点的入度边
pre[e.to] = make_pair(x, i);
// 计算当前路径的最小容量
a[e.to] = min(a[x], e.cap);
que.push(e.to);
}
}
if (a[t]) break;
}
}
2. 增广路径上的边与反向边的容量操作

在这个过程中,通过我们上方记录的 unordered_map<int, pair<int, int>> pre 前驱入度集合,从 T 点开始向前回溯,每次回溯的时候通过访问 int a[MAX_V] 来获得这条增广路上的最小流量,然后更新每一个边和反向边。
int max_flow(int s, int t) {
// 最大流结果
int ret = 0;
while (1) {
// 从 S -> T 使用 bfs 查询一条增广路
bfs(s, t);
// 如果发现容量最小是 0 ,说明查不到了
if (a[t] == 0) break;
int u = t;
while (u != s) {
// 使用 pre 来获取当前增广路中汇点 T 的入度边下标信息
int p = pre[u].first, edge_index = pre[u].second;
// 获取正向边和反向边
Edge& forward_edge = G[p][edge_index];
Edge& reverse_edge = G[forward_edge.to][forward_edge.rev];
// 更新流量
forward_edge.cap -= a[t];
reverse_edge.cap += a[t];
// 逆增广路方向移动游标继续更新
u = reverse_edge.to;
}
ret += a[t];
}
return ret;
}
EK 最大流完整实现

我们用 「Ford-Fulkerson 最大流方法」中的引例再做一次测试,这次使用 EK 算法来求解最大流。
#include <iostream>
#include <vector>
#include <queue>
#include <unordered_map>
using namespace std;
#define INF 0x3f3f3f3f
const int MAX_V = 1e4 + 5;
struct Edge {
int to, cap, rev;
Edge(int _to, int _cap, int _rev): to(_to), cap(_cap), rev(_rev) {}
};
vector<Edge> G[MAX_V];
int a[MAX_V];
unordered_map<int, pair<int, int>> pre;
void add_edge(int from, int to, int cap) {
G[from].push_back(Edge(to, cap, G[to].size()));
G[to].push_back(Edge(from, 0, G[from].size() - 1));
}
void bfs(int s, int t) {
memset(a, 0, sizeof(a));
queue<int> que;
que.push(s);
a[s] = INF;
while (!que.empty()) {
int x = que.front();
que.pop();
for (int i = 0; i < G[x].size(); ++ i) {
Edge& e = G[x][i];
if (!a[e.to] && e.cap > 0) {
pre[e.to] = make_pair(x, i);
a[e.to] = min(a[x], e.cap);
que.push(e.to);
}
}
if (a[t]) break;
}
}
int max_flow(int s, int t) {
int ret = 0;
while (1) {
bfs(s, t);
if (a[t] == 0) break;
int u = t;
while (u != s) {
int p = pre[u].first, edge_index = pre[u].second;
Edge& forward_edge = G[p][edge_index];
Edge& reverse_edge = G[forward_edge.to][forward_edge.rev];
forward_edge.cap -= a[t];
reverse_edge.cap += a[t];
u = reverse_edge.to;
}
ret += a[t];
}
return ret;
}
int main() {
add_edge(0, 1, 16);
add_edge(0, 3, 13);
add_edge(1, 2, 12);
add_edge(2, 3, 9);
add_edge(2, 5, 20);
add_edge(3, 1, 4);
add_edge(3, 4, 14);
add_edge(4, 2, 7);
add_edge(4, 5, 4);
int ret = max_flow(0, 5); // 输出 23
cout << ret << endl;
}
发现同样的,最终结果输出 23 是最大流,符合我们预期结果。
EK 算法时间复杂度及适用情况
由于这次我们使用了 BFS 求解增广路,假设我们的节点数量是 V,边的数量是 E,则 EK 算法的时间复杂度上限是:
\[O(V·E^2)\]分析起来很简单,因为 BFS 找增广路的时间复杂度是 O(E),最多需要 O(V·E) 次查询,所以可得到答案。如果想看证明,我会在「阅读原文」中的「一瓜算法小册」中进行更新。
我们已经知道了 FF 算法和 EK 算法的复杂度:
\[T_{FF} = O(E·F)\] \[T_{EK}=O(V·E^2)\]根据复杂度,我们可以总结出这么一个结论(E 是边的数量,V 是节点数量):
- 当流网络中边少的时候,或者说是一个稀疏图(E < VlogV)时,我们可以选用 EK 算法进行最大流求解;
- 当流网络中边多的时候,或者说是一个稠密图(E > VlogV)时,可以选用 FF 方法求解。
总结
对于最大流算法优化的讨论,我们已经完成了第一步 —— 学习 EK 算法。EK 算法启发我们可以通过 BFS 对增广路进行查询,从而消除 DFS 中查找增广路的时间不确定性,让效率在不同的流网络中可控。
在 Fold-Fulkerson 方法的基础之上,我们了解了增广路,了解了最小割。但是对于流量而言,无论是 FF 方法还是 EK 算法,我们一直都忽视了一个重要的关键,那就是对距离的描述。下一篇文章我们来讲述在距离的帮助下,什么是分层网络,以及 Dinic 最大流算法是如何优化的!
